





 Counseling & Strategic Advice
Counseling & Strategic Advice IP Transactions
IP Transactions Litigation
Litigation PTAB Proceedings
PTAB Proceedings Technology Transfer
Technology Transfer Trademark & Designs
Trademark & Designs U.S. Patent Procurement (Application Drafting & Prosecution)
U.S. Patent Procurement (Application Drafting & Prosecution)








Drafting Claims for Supervised Machine-Learning Systems
Associated People

Supervised machine-learning models are at the heart of some of the biggest advances in artificial intelligence (AI) that have emerged in the past decade. This post revisits the nuts and bolts of drafting claims in this area, and includes two different industry examples of implementing supervised machine learning: medical imaging and speech detection.
In order for a supervised machine-learning model (such as an artificial neural network, a decision tree, etc.) to “learn” a mapping from given inputs to desired outputs, a large training data set of known, correctly mapped inputs and outputs is necessary. Once properly trained on the training data set, the model will hopefully produce correct outputs for new inputs that were not part of the training data set.
A patent application to a particular application of a machine-learning model should include claims to one or more novel aspects of the invention, which can include (1) a particular method of pre-processing raw data before input into the model, (2) the structure of the model itself, and (3) a particular method of post-processing and use of the outputs of the model. Additionally, applicants should consider claiming the method of training the model, including how the training data is obtained and how the training data is applied to the model.
As illustrated in the two examples below, a unique aspect of the structure of model often results in a correspondingly unique method of processing and applying input data to the model or mapping the output of the model to a real-world application. Further, the same novel feature of a machine-learning system can be recited both in a claim to the application of the model, and in a claim to the training of the model.
Example 1 - Analyzing Medical Images
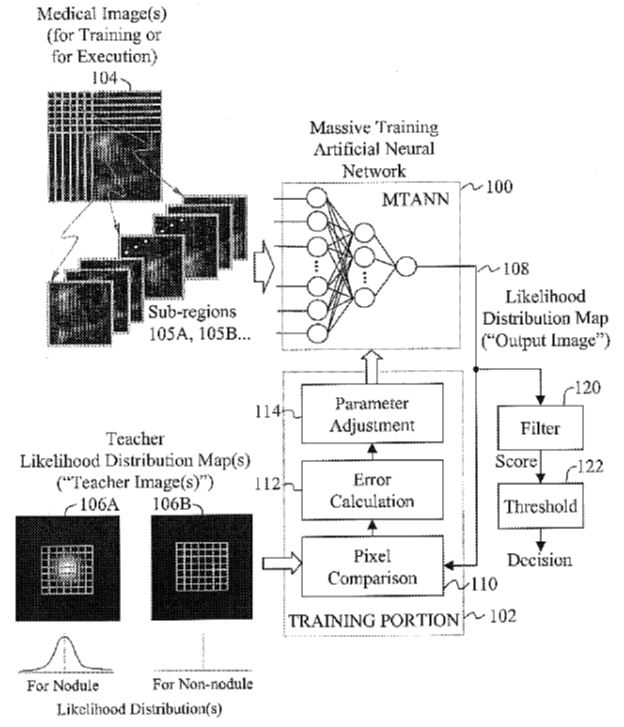
U.S. Patent No. 6,819,790 is directed to a method for detecting abnormalities (e.g, lung nodules or lesions) in medical images, using an artificial neural network. As shown in the figure, the ‘790 training process involves sequentially inputting a plurality of shifted sub-regions of a training medical image into a neural network (MTANN) to obtain an output image, wherein each pixel in the output image corresponds to one of the sub-regions. The output image is then compared to one of two “teacher images” representing, e.g., a nodule or a non-nodule, to generate an error that is used to adjust the weights of the neural network. For example, the teacher image for a nodule can be a two-dimensional Gaussian distribution map having a standard deviation proportional to a size of a typical nodule.
Once trained with a set of training medical images, new medical images can be applied to the MTANN to obtain a new output image, which is evaluated by a scoring algorithm to decide whether or not the new output image corresponds to a nodule.
‘790 Claim 1, directed to a method of training, is reproduced below.
1. A method of training an artificial neural network including network parameters that govern how the artificial neural network operates the method comprising:
receiving at least a training image including plural training image pixels;
receiving at least a likelihood distribution map as a teacher image, the teacher image including plural teacher image pixels each having a pixel value indicating likelihood that a respective training image pixel is part of a target structure;
moving a local window across plural sub-regions of the training image to obtain respective sub-region pixel sets;
inputting the sub-region pixel sets to the artificial neural network so that the artificial neural network provides output pixel values;
comparing the output pixel values to corresponding teacher image pixel values to determine an error; andtraining the network parameters of the artificial neural network to reduce the error.
Note that in ‘790 Claim 1, the particular structure of the model and the specific method of updating the network parameters or weights are not recited. Rather, the novelty appears to reside with the method of obtaining training data, i.e., the use of local sub-windows of an image as inputs to the model, and the use of the different teacher images, e.g., a Gaussian distribution map to represent a nodule. See underlined portion.
Similar novel features are recited in the ‘790 Claim 26, directed to the method of using the trained network model:
26. A method of detecting a target structure in an image by using an artificial neural network, the method comprising:
scanning a local window across sub-regions of the image by moving the local window for each sub-region, so as to obtain respective sub-region pixel sets;
inputting the sub-region pixel sets to the artificial neural network so that the artificial neural network provides, corresponding to the sub-regions, respective output pixel values that represent likelihoods that respective image pixels are part of a target structure, the output pixel values collectively constituting a likelihood distribution map; and
scoring the likelihood distribution map to detect the target structure.
Thus, in the ‘790 patent, the novel method of processing an image before input to the network (using local sub-windows) is recited both in a claim to a method of training and in a claim to a method of detecting a target structure.
Example 2 – Speech Detection
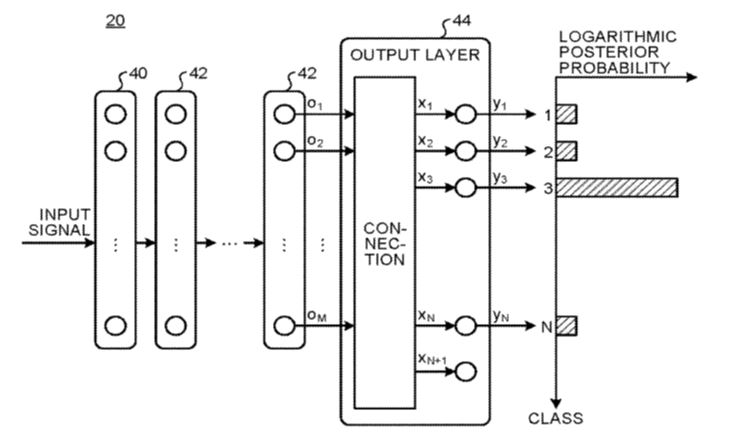
U.S. Patent No. 10,839,288 is directed to a speech detection device to detect whether a speech signal contains a specified search pattern. The ‘288 speech detection device uses a trained neural network, shown below, to determine whether any part of the speech signal corresponds to the specified search pattern. The ‘288 network has an input layer 40, at least one hidden layer 42, and an output layer 44 that produces N+1 values. However, only N of the values produced by the output layer correspond to the posterior probability that the input belongs to one of the N output classes. See the output XN+1, which does not correspond to an output probability. However, in the ‘288 system, the output probability values are calculated by subtracting the value XN+1 from each of the output values X1 to XN.
When training using a known input signal and known target outputs for each of the N output classes, the desired output corresponding to the N+1th output value is separately set to a predetermined constant value. Moreover, for training, only one of the N target outputs is non-zero for a given input signal.
‘288 Claim 14, directed to a training method, is reproduced below.
14. A training method, comprising:
training a neural network that outputs a posterior probability that an input signal belongs to a particular class of a plurality of classes, wherein an output layer of the neural network includes N units each respectively corresponding to one of the plurality of classes, N being an integer of 2 or larger, N units receiving the respective inputs and generating the respective outputs, the output layer includes one additional unit, the one additional unit receiving the respective input without generating the respective output,
the training comprises:
supplying a sample signal known in advance to belong to the particular class to the neural network;
acquiring, for each of the units at the output layer, (N+1) input values that are obtained by connecting signals output from a layer immediately preceding the output layer according to a set parameter;
supplying the input values to a function for calculating the posterior probability to generate a probability vector including (N+1) probability values respectively corresponding to the units at the output layer; and
updating a parameter included in the neural network in such a manner to reduce an error between a teacher vector and the probability vector, the teacher vector including (N+1) target values respectively corresponding to the units at the output layer,
wherein a target value in the teacher vector corresponding to the additional unit is a predetermined constant value.
As evident from ‘288 Claim 14, the structure of the neural network and the training method are broadly recited and seemly conventional, except for the “extra” output not corresponding to one of the output classes, and the teacher value for that extra output being a predetermined constant value. Further, note that ‘288 Claim 14 is very broad in that it does not mention a particular application of the model, such as speech detection.
Thus, the structure of the ‘288 model, with the extra output value, results in the use of a uniquely constructed teacher vector for training the model. Accordingly, novel aspects of the ‘288 patent are the structure of the output layer and the corresponding method of training, which results in a better-trained model compared to conventional models.
The above examples touch the surface of different, but effective, claiming strategies that can be used in different industrial applications that incorporate a supervised machine-learning model. Both examples have broad claims with respect to their ultimate end-use (no mention of medical imaging or speech detection), but are focused on a specific portion of the machine-learning system. In future posts, we look forward to diving into more details on the different challenges that arise in claiming AI inventions in different industries.